
Authors:
(1) Xian Liu, Snap Inc., CUHK with Work done during an internship at Snap Inc.;
(2) Jian Ren, Snap Inc. with Corresponding author: [email protected];
(3) Aliaksandr Siarohin, Snap Inc.;
(4) Ivan Skorokhodov, Snap Inc.;
(5) Yanyu Li, Snap Inc.;
(6) Dahua Lin, CUHK;
(7) Xihui Liu, HKU;
(8) Ziwei Liu, NTU;
(9) Sergey Tulyakov, Snap Inc.
Table of Links
3 Our Approach and 3.1 Preliminaries and Problem Setting
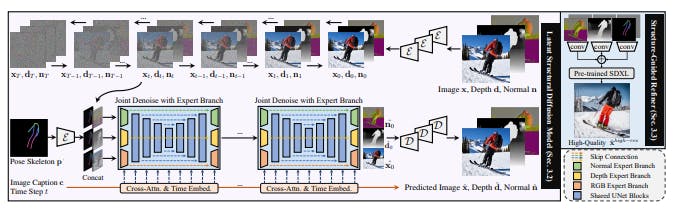
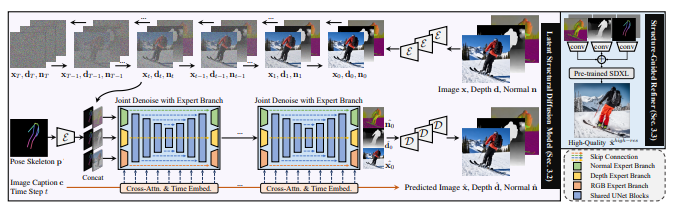
3.2 Latent Structural Diffusion Model
A Appendix and A.1 Additional Quantitative Results
A.2 More Implementation Details and A.3 More Ablation Study Results
A.5 Impact of Random Seed and Model Robustness and A.6 Boarder Impact and Ethical Consideration
A.7 More Comparison Results and A.8 Additional Qualitative Results
2 Related Work
Text-to-Image Diffusion Models. Text-to-image (T2I) generation, the endeavor to synthesize highfidelity images from natural language descriptions, has made remarkable strides in recent years. Distinguished by the superior scalability and stable training, diffusion-based T2I models have eclipsed conventional GANs in terms of performance (Dhariwal & Nichol, 2021), becoming the predominant choice in generation (Nichol et al., 2021; Saharia et al., 2022; Balaji et al., 2022; Li et al., 2023). By formulating the generation as an iterative denoising process (Ho et al., 2020), exemplar works like Stable Diffusion (Rombach et al., 2022) and DALL·E 2 (Ramesh et al., 2022) demonstrate unprecedented quality. Despite this, they mostly fail to create high-fidelity humans. One main reason is that existing models lack inherent structural awareness for human, making them even struggle to generate human of reasonable anatomy, e.g., correct number of arms and legs. To this end, our proposed approach explicitly models human structures within the latent space of diffusion model.
Controllable Human Image Generation. Traditional approaches for controllable human generation can be categorized into GAN-based (Zhu et al., 2017; Siarohin et al., 2019) and VAE-based (Ren et al., 2020; Yang et al., 2021), where the reference image and conditions are taken as input. To facilitate user-friendly applications, recent studies explore text prompts as generation guidance (Roy et al., 2022; Jiang et al., 2022), yet are confined to simple pose or style descriptions. The most relevant works that enable open-vocabulary pose-guided controllable human synthesis are ControlNet (Zhang & Agrawala, 2023), T2I-Adapter (Mou et al., 2023), and HumanSD (Ju et al., 2023b). However, they either suffer from inadequate pose control, or are confined to artistic styles of limited diversity. Besides, most previous studies merely take pose as input, while ignoring the multi-level correlations between human appearance and different types of structural information. In this work, we propose to incorporate structural awareness from coarse-level skeleton to fine-grained depth and surface-normal by joint denoising with expert branch, thus simultaneously capturing both the explicit appearance and latent structure in a unified framework for realistic human image synthesis.
Datasets for Human Image Generation. Large datasets are crucial for image generation. Existing human-centric collections are mainly confronted with following drawbacks: 1) Low-resolution of poor quality. For example, Market-1501 (Zheng et al., 2015) contains noisy pedestrian images of resolution 128 × 64, and VITON (Han et al., 2018) has human-clothing pairs of 256 × 192, which are inadequate for training high-definition models. 2) Limited diversity of certain domain. For example, SHHQ (Fu et al., 2022) is mostly composed of full-body humans with clean background, and DeepFashion (Liu et al., 2016) focuses on fashion images of little pose variations. 3) Insufficient dataset scale, where LIP (Gong et al., 2017) and Human-Art (Ju et al., 2023a) only contain 50K samples. Furthermore, none of the existing datasets contain rich annotations, which typically label a singular aspect of images. In this work, we take a step further by curating in-the-wild HumanVerse dataset with comprehensive annotations like human pose, depth map, and surface-normal map.
This paper is available on arxiv under CC BY 4.0 DEED license.