
Authors:
(1) Xian Liu, Snap Inc., CUHK with Work done during an internship at Snap Inc.;
(2) Jian Ren, Snap Inc. with Corresponding author: [email protected];
(3) Aliaksandr Siarohin, Snap Inc.;
(4) Ivan Skorokhodov, Snap Inc.;
(5) Yanyu Li, Snap Inc.;
(6) Dahua Lin, CUHK;
(7) Xihui Liu, HKU;
(8) Ziwei Liu, NTU;
(9) Sergey Tulyakov, Snap Inc.
Table of Links
3 Our Approach and 3.1 Preliminaries and Problem Setting
3.2 Latent Structural Diffusion Model
A Appendix and A.1 Additional Quantitative Results
A.2 More Implementation Details and A.3 More Ablation Study Results
A.5 Impact of Random Seed and Model Robustness and A.6 Boarder Impact and Ethical Consideration
A.7 More Comparison Results and A.8 Additional Qualitative Results
A APPENDIX
In this supplemental document, we provide more details of the following contents: 1) Additional quantitative results (Sec. A.1). 2) More implementation details like network architecture, hyperparameters, and training setups, etc (Sec. A.2). 3) More ablation study results (Sec. A.3). 4) More user study details (Sec. A.4). 5) The impact of random seed to our model to show the robustness of our method (Sec. A.5). 6) Boarder impact and the ethical consideration of this work (Sec. A.6). 7) More visual comparison results with recent T2I models (Sec. A.7). 8) More qualitative results of our model (Sec. A.8). 9) The asset licenses we use in this work (Sec. A.9).
A.1 ADDITIONAL QUANTITATIVE RESULTS
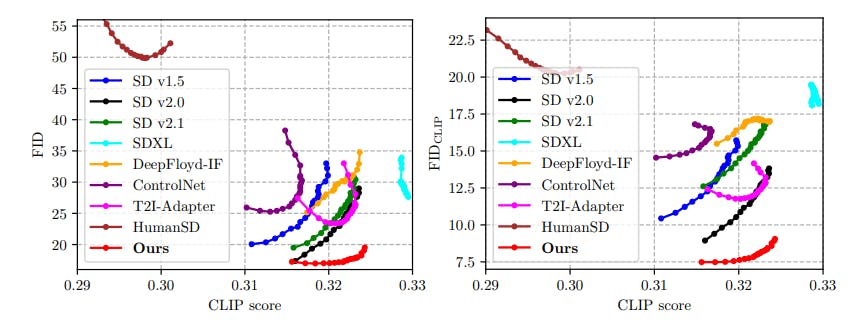
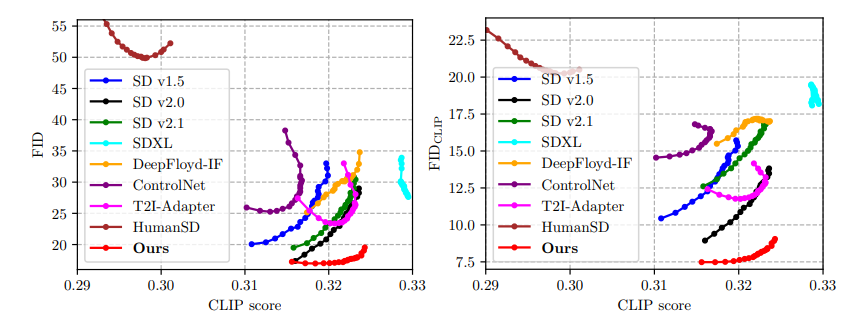
FID-CLIP Curves. Due to the page limit, we only show tiny-size FID-CLIP and FIDCLIP-CLIP curves in the main paper and omit the curves of HumanSD (Ju et al., 2023b) due to its too large FID and FIDCLIP results for reasonable axis scale. Here, we show a clearer version of FID-CLIP and FIDCLIP-CLIP curves in Fig. 4. As broadly proven in recent text-to-image studies (Rombach et al., 2022; Nichol et al., 2021; Saharia et al., 2022), the classifier-free guidance (CFG) plays an important role in trading-off image quality and diversity, where the CFG scales around 7.0 − 8.0 (corresponding to the bottom-right part of the curve) are the commonly-used choices in practice. We can see from Fig. 4 that our model can achieve a competitive CLIP Score while maintaining superior image quality results, showing the efficacy of our proposed HyperHuman framework.
Human Preference-Related Metrics. As shown in recent text-to-image generation evaluation studies, conventional image quality metrics like FID (Heusel et al., 2017), KID (Binkowski et al. ´ , 2018) and text-image alignment CLIP Score (Radford et al., 2021) diverge a lot from the human preference (Kirstain et al., 2023). To this end, we adopt two very recent human preference-related metrics: 1) PickScore (Kirstain et al., 2023), which is trained on the side-by-side comparisons of two T2I models. 2) HPS (Human Preference Score) V2 (Wu et al., 2023), which takes the user like/dislike statistics for scoring model training. The evaluation results are reported in Tab. 4, which show that our framework performs better than the baselines. Although the improvement seems to be marginal, we find current human preference-related metrics to be highly biased: The scoring models are mostly trained on the synthetic data with highest resolution of 1024 × 1024, which makes them favor unrealistic images of 1024 resolution, as they rarely see real images of higher resolution in score model training. In spite of this, we still achieve superior quantitative and qualitative results on these two metrics and a comprehensive user study, outperforming all the baseline methods.
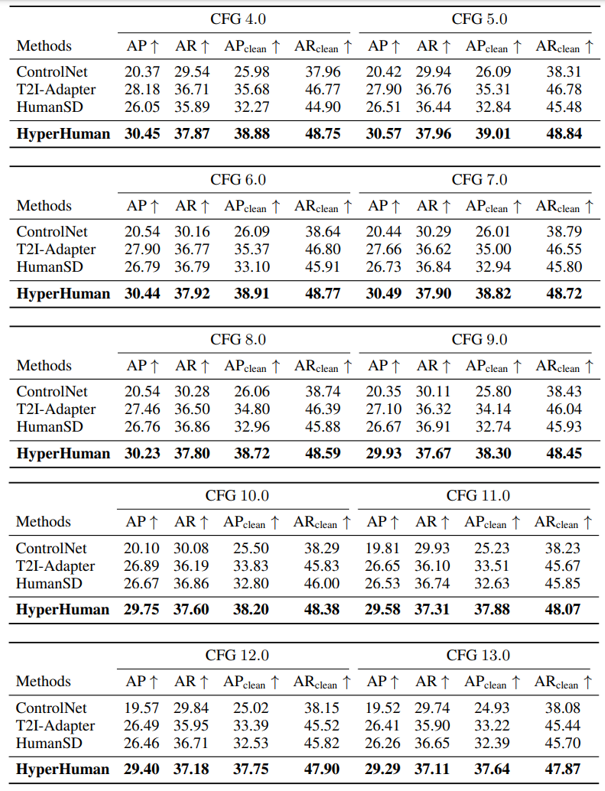
Pose Accuracy Results on Different CFG Scales. We additionally report the pose accuracy results over different CFG scales. Specifically, we evaluate the conditional human generation methods of ControlNet (Zhang & Agrawala, 2023), T2I-Adapter (Mou et al., 2023), HumanSD (Ju et al., 2023b), and ours on four metrics Average Precision (AP), Average Recall (AR), clean AP (APclean), and clean AR (ARclean) as mentioned in Sec. 5.1. We report on CFG scales ranging from 4.0 to 13.0 in Tab. 5, where our method is constantly better in terms of pose accuracy and controllability.

This paper is available on arxiv under CC BY 4.0 DEED license.